Primer on Elliptic Curve Cryptography
Just dumbing down the ideas behind elliptic curve cryptography so that a highschooler can understand.
I'm going to be giving a talk that gives a quick primer on elliptic curve cryptography. But I thought I'd do a writeup on it before the presentation so that people who want to read up on it before-hand can do so. That, and also writing things down actually fleshes out what I'm about to talk about.
When building information systems, you're either storing information, or sending it somewhere else. But for every interaction you have with information, malicious actors will always be attempting to either steal or sabbotage information, impersonate someone, or fraudulently deny that they have ever committed a transaction.
Our goal is to thwart these malicious actors, and the predominant strategy for this has been to have intended actors be very easily able to disseminate and store information, while making it difficult for malicious actors to cause harm.
The Discrete Log Problem (or rather the Elliptic Curve Discrete Log Problem)
There are many strategies for difficulty, but with elliptic curves (in finite fields of prime order, which is a space we will discuss a bit later), the difficulty has been brought on by the difficulty in solving the discrete log problem.
That is, we have some function that takes two parameters of a particular group (for example, two points on an elliptic curve), which returns another element of that group. We repeatedly apply that function to a single element of that group, for a very large number of times. The result of that function invocation could be public information which is potentially used to identify an actor, along with the element that the function was applied on. Meanwhile, the very large number of times where the function was applied is private information that an actor will have derived before generating that public information. Everyone knows the public information—the result of the function invocations, and the element in which the invocation was applied to—but only the actor knows how many times they've called that function to derive that public information.
To put it in math terms, let's define some function , which takes two parameters and of a group. What we're doing is given some publicly-known information. Where element , we're invoking it with some number of times:
The element along with the result is public information, but is private information that should never be shared.
The basis of the elliptic curve discrete log problem is that even if we are publicly given the element , the result , and the underlying algorithm behind the hypothetical function, it should still be absolutely impossible to recover .
The function
Previously, we were introduced to the function, which takes two elements from a group, and returns another element from that same group.
But what does it mean to operate on two elements from a group to return an element of a group, and how does it relate to elliptic curves?
In the context of elliptic curves, we have a curve that looks like the one below:
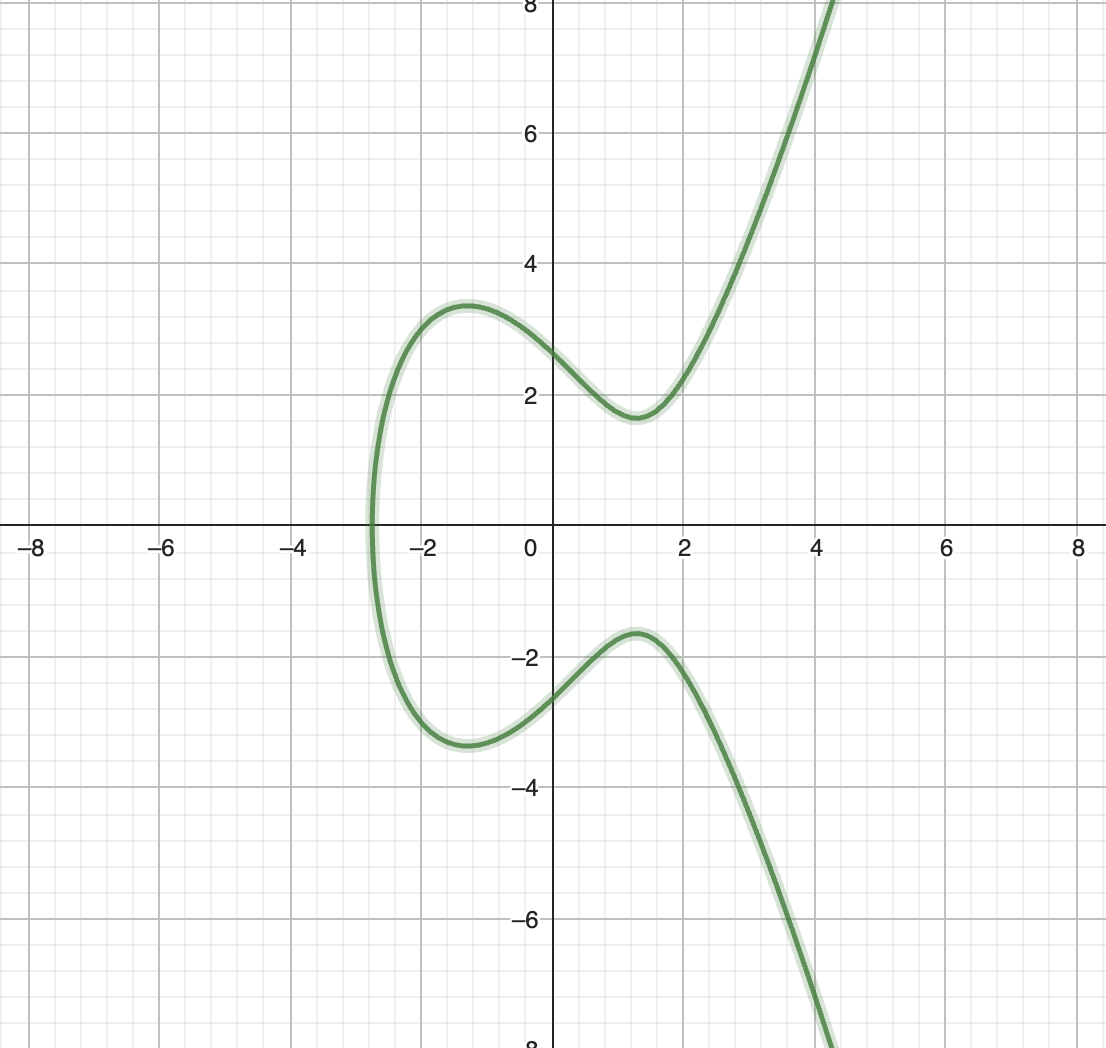
We pick two points and on that curve, and we draw a straight line that crosses the two points, that line will actually end up crossing a third point on the curve.

We call it and not just is because is not our result of our function. Fortunately, finding from is very easy: it's merely the result of vertically reflecting to find .
And if and are equal to eachother (e.g. ), then finding the result involves imagining that you are drawing a line that crosses two points that are negligibly different from each other, thus forming what is known by mathematicians a "tangent" line. And that tangent line will also cross another point, which is our , which we then flip veritcally to find .
In projective geometry, the idea of counting a tangent of a line as two distinct points is called "counting multiplicities".
Just a quick spoiler: regardless of whether you decide to draw line that crosses first with or with , we will always get the same . This effectively renders the function to have a "commutative property", that is .
Later, we'll show that the the above elliptic curve rendered from the Weierstrass form (where ), also shares associative properties.
Some math notations, and an introduction to Abelian groups
Earlier, I introduced the function. But writing it out gets a little wordy.
Mathematicians have instead opted for—rather confusingly—the infix operator to express a 2-parameter operation on group elements.
That is, given two elements and of a group, the expressed operation is instead expressed as:
Yes, the symbol is used for something that may not be intuitively an addition.
It could be argued that there is a good reason for this.
For one, even with the abbreviation, repeating the expression of several "additions", -number of times gets repetitive:
So, we can just express the above as a scalar multiplication of G by the quantity :
The expression is certainly a lot more compact than .
So in short, we settled with:
Other arguments behind why is that a lot of cryptographic primitives form an Abelian group.
That is, they have the following properties:
- Commutativity: the expression can equally be expressed as
- Associativity: regardless of if you compute or , the results will be the same
- Existence of an identity element: given some element , we can compute
- Existence of an inverse: that is, not only do we have some , but also some , such that . And in the case of Abelian groups that attempt to allude to the concept of an "addition", rather than expressing , we'd express , analogous to a subtraction.
In the context of elliptic curve group operations (called "addition" going forward), the identity element isn't left to some variable name of , of course. That will be discussed later.
Abelian group scalar multiplications
Earlier I mentioned that we are computing some such that we are repeatedly applying , all the way until has been added number of times.
The problem is that can be a ridiculously large number. Sometimes a number so large, by some estimates, it exceeds the total number of atoms in the known universe!
If computers are really bad at iterating over the number of atoms in a glass of water, there is no way we're going to be able to compute a number as large as the total number of atoms in the unverse, or anything near it!
Good thing is, Abelian groups have an associative property.
Thanks to this, we can group operations together.
For example, in the expression , rather than computing , instead, let's compute .
When we first compute the left set of additions , we already know the value of the second , thus saving us a computation.
And we can boadly apply this to eight additions.
This should yield just 3 computations rather than 8.
The double and add algorithm
We see that there is potential to cutting down computations from to just .
But the algorithm above implies that we're using something similar to dynamic programming. That is, to memoize individual results.
This requires of auxiliary space.
We can do better. We can reduce that down to just auxiliary space.
This is where the double and add algorithm comes in.
The basic gist of the algorithm is this:
- start with some identity element as the result
- convert the number into binary digits, and iterate through each digits from most-significant bit, down to the last significant bit
- if the digit is encountered, set to
- otherwise set to
Now you've saved time from down to , with no auxiliary space required.
Possible Side-Channel attack
So with the double and add algorithm, we see that one branch of the if-statement runs two operations, where as the other only computes one.
Problem is, someone can be snooping in on CPU cycles and use it to recover the secret number!
A mitigation to the side-channel attack is to resort to the Montgomery ladder.
Why is it easy to go one way but hard the other
It's easy to go one way because we're able to look at the binary structure of an integer, but going the other way is effectively a really difficult search problem, and there are just no (known) shortcuts.
Math of drawing lines across elliptic curves
I introduced the curve, that we call the "elliptic curve". But of course, it's difficult to draw such a curve perfectly. Not to mention, computers can't work with drawings very well.
Instead, they can work with math.
They have support for additions, subtractions, exponentiation, etc.
So let's use good old math for this.
Elliptic curves can be expressed as the equation:
That equation describes what is known as a "Weierstrass form", which knowing this name may be useful when discussing ECC.
Of course and are variables that relate to eachother, but and are constants that we pick right before we interact with others.
Regardless, now our problem is, if we happened to have picked two points and on a curve, how would we find the -coordinate of the third point, and the corresponding -coordinate?
Here is where we will do some derivations for the math to recover those values.
Projective Geometry
In high school, when drawing two parallel lines, both will remain parallel forever.
This is called affine geometry.
However, with elliptic curves as used in cryptography, we're going to be taking advantage of another branch of geometry called projective geometry.
Projective geomoetry shares all the same properties of affine geometry, but one important facet of projective geometry that we're going to take advantage of is that parallel lines are not parallel in projective geometry.
Instead, they intersect at a point, and that point is the point at infinity.
We'll see later that this is a powerful concept that we can take full advantage of.
Finding the x-coordinate of the third point
Let's define as a point on the curve and on that same curve.
We'll first need to define the equation of the line that is secant to and , and it will be this:
Where we can think of as the slope of the line, and is where the line intercepts at the y-coordinate, when , or simply known as the "-intercept".
Our isn't just any value; it's dependent on the positions of and , for , and . To compute the slope, it's merely the "rise over the run", or rather the rate of change of , with respect to . In other words, it's a ratio, and the ratio is computed by calculating the differences in the y coordinates with respect to the x-coordinates.
So:
To find the -intercept , we'd simply sample a point on the equation of the line, and solve for . We'll just take the coordinates from .
OK, this is nice to know and all, but what can we do with this?
Well, we need to find the third point on the curve.
Can we use algebra for this?
We can see that both the equation of the line, and the equation of the curve have a -coordinate.
How about we do a substitution? After all, the points on the line intersect with the points of the curve. Does this mean that both the line and the curve will intersect at all three points? Let's try:
We can see that the left-hand side is quadratic with respect to x, and the right-hand side is cubic. Subtracting a quadratic from a cubic will still yield a cubic equation.
Let's do that.
Now, here is a property that you have to remember: for cubic polynomials—such as the one that we derived on the right-hand side of the equation above—there are three possible values of that we can plug in for the equation to hold (e.g. the cubic polynomial to equal zero).
Let's call them , , and .
We're getting close. We already know and . Now all we need to do is find .
Let's reinterpret the polynomial from above into some other polynomial where we re-express the constant coefficients of the polynomial as some other set of constants:
Where , , , .
We can infer this from factorizing the cubic expression like so:
Expanding the right-hand side of the above equation should yield:
Now, from the earlier derivation of our polynomial, we saw that the coefficient associatd with is just , so we can simply get rid of the
That is:
And also, remember, that above polynomial should equal to the one we derived earlier.
Now let's focus on the second term of both of the polynomials. We see that the second term are equal to each other.
Just get rid of the and the negative, and we get:
And we can finally solve for :
Finding the y-coordinate of the third point
Finally, to solve for , we just plug everything into the equation of the line:
What if the two points on the curve are equal to each other?
So, what if two points on the curve are equal to each other.
This would mean that if we naively plug in , which is indeterminate.
This means that we will need to think outside the box.
A primer on differential calculus
The trick to do is to pretend that we have a point that slightly differs on the curve, where the difference is so small, it may as well be 0, but we still get the slope of it.
I'm not going to go over the entire math behind it. But the gist of it goes like this.
Given some function , we want to find the instantaneous rate of change with respect to its input.
That is, as some value approaches the input of , we will get the differentation at point , written as , defined as the limit of , as approaches .
As a short-hand, the above can be written like so:
Alternative as some value approaches , we will get the differentation at point , written as , defined as the limit of , as approaches .
It can be abbreviated to:
Effectively, is giving you the slope of some line at point .
We're just going to go over one example, and afterwards, I'm just going to include some common patterns that have been discovered.
The beauty of the "limit" operator as denoted by is saying that we want to know what does the expression tend to as approaches . We might not know much about the value at , but we can give something that is pretty much the answer that we have been looking for.
This is great for functions where a function is not defined at .
Let's take the function . The function is indeterminate at , even though . So, the limit expression is saying that we are going to find some expression that approaches as approaches . And the limit operator will help us reveal that the limit of as approaches is simply 0.
Now onto computing an ifinitesimally small change in x to find the slope at .
Let's take the example of . The slope at is derived as follows:
Therefore .
There are many more rules like this.
Here's a handful of rules:
- Constant rule:
- Identity rule:
- Sum rule:
- Product rule:
- Chain rule:
Then we can compose those above rules to create more rules.
For example, the coefficient rule is a combination of the constant rule and product rule:
And then, there is the positive integer power rule, which is just the product rule recursively applied, all the way until we reach the identity and constant rule.
I'll leave it as a exercise to prove that the positive integer power rule is pretty much , e.g. .
Deriving the slope of the line at a point on the elliptic curve
OK, now that we have summarized some differentiation rules above, let's go ahead and derive the equation of the curve that will help us find the slope of the line tangent to a point curve.
Recall that the equation of the curve is defined as:
Also recall that is the slope of the point at , pretending that we're trying to find a slope of the points and , as approaches 0.
In math terms, we're looking for some such that:
In the equation of the curve, we're actually trying to find the change in with respect to .
This means we're trying to find .
We're going to apply the operator on both sides of the equation.
Trying to find , and then ultimately derive will require some clever hacks. We'll get back to it later.
Let's start with the right-hand side.
Therefore .
Now, onto the left-hand side of the equation.
What we're interested in is what happens to for some . You can think of being a function of .
So, we can go with chain rule.
The chain rule will give the derivative as the product of the differentation and
So, we get .
And remember, we're trying to find .
So, isolating from the resulting equation and we get:
What if the two points are vertical reflections of each other?
At this point, we stop.
We just assume the result is a point at infinity.
And recall that "adding" a point to a point that is a mirror reflection of is as if , and .
Summary of elliptic curve "addition"
When two points are different, for and the slope is simply defined as:
And for , then we use the derivative:
The -intercept of the line is defined as:
Finally, to find the third point:
And if , then we do nothing, and just have the "addition" yield the point at infinity.
Relating back to Abelian groups
Commutativity
As we can see, drawing a straight line that crosses between two points and also crosses a third point on the curve. This is true regardless of from which direction you decided to draw that line. Did you decide to have that line cross first, or first? The result is the same! The order doesn't matter.
Associativity
What's cool about this is that we can also apply this operation with three points , , and .
Regardless of if you start by attempting to find some by first drawing a line through and , or through and , after you've drawn a line through and the remaining point where you didn't "add" yet, you'll still get the same .
Not convinced?
Stay tuned for the proof.
Identity element
This is where Mathematicians used their imagination.
It may sometimes be emphasized that and shouldn't be vertical reflections of each other?
What happens if they are?
The resulting line will never intersect anywhere on the curve in affine geometry, but instead will intersect at a point at infinity in projective geometry, which we will denote as .
It may sound blasphemous, but there is an important opportunity for us here.
For one, we can treat this as the "identity element".
Imagine if and were indeed vertical reflections of each other.
Then computing will give us .
How can we use the fact that there exists some that we can play around with?
Well, imagine if we have , and draw a perfectly vertical line that crosses .
It will of course go on for . We can think of this as . Now, the thing about crossing and , it will also cross some point that is a reflection of .
And remember the operation: the idea is, once we've crossed a third point, we reflect vertically!
This means that crossing and will cross the vertical reflection of , which we will call , and doing so will require flipping vertically, thus giving us again.
This means that yield , or .
Existence of an inverse
I've already mentioned earlier that if and were vertical reflections of each other, then we get some point at infinity denoted as . In other words , only if and are vertical reflections of each other.
But if , is there a ?
Yes!
If is a vertical reflection of , then this merely means that could simply be denoted as .
In other words, "negation" is merely the act of vertically reflecting .
Bonus: Proof of Associativity
Commutativity is obvious: regardless of which direction you start to draw the line between and , you will always land on the same point .
But associativity is a bit more tricky.
For many, it's not enough to look at a drawing and be satisfied by the associative properties. Is there a case for some , , and , such that ?
Fortunately, we have proof that this will not be the case.
Using Bezout's Theorem
Given two polynomials of degrees and , then they will intersect at exactly points (counting multiplicity), and no more unless they have a component in common.
If we are to draw lines that are the result of summing , we see that it yields 3 lines, and all 3 lines will intersect at exactly 9 points.
Likewise for .
If we are to treat both sets of lines as curves on a projective plane, then both sets of lines can be thought of as cubic polynomials, and all of them will intersect at exactly 9 points, including the points crossing and .
Using Cayley-Bacharach theorem
Given three points , , and on an elliptic curve, we aim to show that .
To prove associativity, we will utilize the Cayley–Bacharach theorem, which asserts that for any cubic curve over an algebraically closed field, if the curve passes through any eight points, it also passes through a ninth point (counting multiplicities), including the point at infinity.
Consider the set of points: , , , , , , , and the point at infinity. Suppose we construct two lines: one passing through and intersecting the curve again at , and another passing through and intersecting the curve again at . By reflecting these sums and about the curve, we obtain points and .
These intersections provide us with two groups of lines whose intersections with the cubic yield eight distinct points (considering each pair of points contributes an intersection). By the Cayley–Bacharach theorem, any cubic passing through these eight points must also pass through a ninth point, which is exactly where intersects the curve, and also where intersects.
If these points were different, the sets would intersect at a tenth distinct point, violating Bézout's theorem, which states that a line and a cubic can intersect at no more than three points. Thus, we conclude that , proving associativity.
How the Cayley-Bacharach theorem work
By Bezout's Theorem, we're effectively saying that two cubics and in projective space with no common components will intersect at points (counting with multiplicity). If a passes through all 9 points (counting multiplicity) of the intersections of and , then can only be expressed as the linear combination , where , by the properties of projective geometry. That is, the degrees of freedom has been restricted to only pass through the points.
Building on this, the Cayley-Bacharch theorem further refines our understanding of these intersections. The Cayley-Bacharch theorem implies that if shares eight of the nine intersections of that of and , then it must also pass through the ninth intersection point.
Applying this back to the intersections of 3 lines with the curve, what we're trying to do is that if we have a curve, intersect 3 lines on that curve, then constructing a third curve will necessarily require that the third curve is a linear combination of the curve and the 3 lines.
The general idea is, once the first 8 points have already been selected, the degrees of freedom that we now have is highly constrained, to the point that all three curves are linearly dependent on all 9 points.
N.B. multiple lines on a plane forms a polynomial
So earlier I seemed to have treated distinct lines as a single polynomial curve.
Is that even legal?
Yes.
We're all familiar with the equation of the line of the form .
But there is nothing stopping us from interpreting it as the impiclit equation .
As we can see, that equation of the line is effectively a polynomial. What happens if we compute the product of several lines to give us a polynomial, that is for example ?
Well, if we are to plot out the result of the implicit polynomial, this would yield a curve that looks no different than as if all lines were entirely distinct!
Try it out yourself.
Elliptic curve in finite fields
In the above derivations, if you are familiar with high school math, you'd think that we were working with real numbers.
Yes, perhaps the math would work with real numbers.
But the math would work with whatever math there is with a concept known as "field".
Real numbers are fields.
But cryptography doesn't always work with real numbers.
What they instead work with is finite fields of prime order.
Problem: computers are really bad with real numbers
Computers are really bad with real numbers.
Yes, two CPUs implementing the exact same architecture will come up with the same exact numbers, given the same exact set of instructions, but not everyone is on the same CPU architecture. At the time of writing this, people on their laptops are often on Intel-based systems. Apple has made the push for something based on ARM. And a lot of smartphones are also on ARM-based CPUs. And not to mention, RISC-V is a new contender in the CPU architecture space.
Every one of them will give you different results.
Not to mention, different implementation details will ultimately end up yielding different results. And even small discrepancies can really throw everything off.
Solution? Work exclusively with integers?
We could perhaps ditch real numbers and aim for integers.
But here's the problem with integers: they don't have a very good definition for a multiplicative inverse.
The division problem
Before we start computing divisions of integers, we got to ask ourselves: what is a divison?
Well, as far as humans and counting is concerned, divisions is just trying to discover how many times can one number fit into another.
For example, how many times can fit into ? The answer is .
But if we are to think strictly in terms of group theory, a divison is to take some and multiplying it by the multiplicative inverse of . That is, the multiplicative inverse of is some quantity such that , which is impossible with integers.
Group theory and the multiplicative inverse
Recall that in an Abelian group, we have four properties:
- Commutativity
- Associativity
- Identity element
- Inverse
With integer addition and multiplication we get commutativity and associativity. We may have an identity element with additions, but multiplications? What do we get?
Well, we still get 1, but if we are to multiply two integers and , can we ever get the number ?
Of course, with integers this is literally impossible.
Forget real numbers; forget integers. Finite fields of prime order is here to save the day
So we just found out we may have some "identity" element with integers. But we lose the multiplicative inverse with integers. That is, there can never exist two integers and where their product will yield .
This is where we ditch real numbers and the integer space, but instead work with another much smaller integer space called finite fields of prime order.
Working within a finite field means to work with integers to , where is a prime number.
The math with finite fields is very similar to integers and real numbers, but like elliptic curve groups, the "+" operator and—now—multiplication works slightly differently.
All operations not only give the "addition" (as intuitively understood by the act of addition, since we were taught in elementary and high school), but additions greater than equal to the prime wraps around.
For example, given some finite field with prime , the sum would yield . The expression is similar to the integer arithmetic , but mathematicians prefer to "abbreviate" things using the congruence , with—in our—.
With finite fields, we most certainly have Abelian group properties, for both the additive and multiplicative groups, but the multiplicative aspects also has one additional property: distributivity.
That is, .
Finite fields actually saving the day for multiplicative inverses
Other than distributivity, we also retain the one important property: multiplicative inverse.
That is, given some , we can find some such that:
Again, this is possible, because the modulo operator forces everything to just "wrap around", and we want to find some (the multiplicative inverse of ) such that their products "wrap around" to the value .
Notation for multiplicative inverse
In real numbers, the expression can also be expressed as .
Likewise for finite fields.
And better yet, we can express the property of the multiplicative inverse as:
.
Modular arithmetics
OK, so I used the operator previously.
For those not familiar with that operator, it's pretty much a facet of math that we were taught roughly around the 4th grade.
It's the idea of "division with remainder". This "4th grader math" has the fancy name "Euclidean division", which is named after the mathematician who is known for having formalized and documented it in his work.
It goes like this: take for example the division divided by .
does not divide .
But does fit into up to times, which would yield the number . What remains is .
The operator only cares about the remainder in a Euclidean divison, which in the case of the division divided by , the modulo .
Multiplicative inverses in finite fields
OK, with finite fields, we can most certainly have an and a such that their product yields (where is a prime). Such an operation is literally impossible with integers, but possible with finite fields.
But now, how do we find the multiplicative inverse?
Perhaps using the greatest common divisor ()?
For the record, the function takes two integers, and attempts to find their greatest common divisor.
So, if we are to pick some integer , where is prime, then the .
We may be onto something.
There's also Bezout's identity.
It stipulates that the is the linear combination:
That is, we can find some x, and some y, such that the above linear combination holds true.
But in the case of and , where—recall that— is prime, we get:
If we compute the modulo of both sides, we get
In the above equation, because is a multiple of , then effectively "wraps" around to .
So then
And thus
The multiplicative inverse
To find the multiplicative inverse, we can take full advantage Bezout's Identity.
Again, in modular arithmetic:
And remember cancels out, so we're left with:
We can then use the extended Euclidean algorithm to derive Bezout's identity.
And remember, the whole idea of the multiplicative inverse is that there exists some and , such that their product yields . This means, using Bezout's identity, we can effectively find the multiplicative inverse quite easily.
Euclidean algorithm
Before we talk about the extended Euclidean algorithm, let's first talk about the Euclidean algorithm.
The Euclidean algorithm is just a fancy word for an algorithm that repeatedly applies the Euclidiean division between a dividend and divisor, all the way until we reach 0.
The Euclidean algorithm can be succinctly defined as the recurrence:
Extended Euclidean
We've seen a very simple algorithm to compute the greatest common denominator of two (positive) integers.
Now onto the extended Euclidean algorithm, which should help us find the coefficients an in Bezout's identity, .
If and isn't a representation of the base case (that is ), then the above equation can also be expressed as:
But, careful, just because , doesn't mean that is .
Instead, the and the are something different, so we'll use and , that is:
So, we will need to do more algebraic manipulation to make finding and easy.
The trick would be to look at one definition of the modulo operator.
One plausible definition of the operator is
So we can rewrite the above equation representing one level below the start of the recursion as:
Now we see that
And we can see that and .
Of course, the expression doesn't really tell us much about and itself. But, we will get a good insight once we reach the base case.
Recall that going one level below the recursion to gives us which is also equal to .
We can clearly draw the parallel between . So not only does have a base case, but so will the recurrence equation.
Once we reach the base case, we'll just set , and shouldn't matter, since is equal to zero.
We're going to write some psuedopython to represent the recurrence.
We're not actually going to return some equation. Instead, we're just going to return the , and coefficients.
def extended_gcd(a, b):
if b is 0:
return (1, 1)
x1, y1 = extended_gcd(b, a % b)
return (y1, x1 - (a//b)*y1)
Divisions in finite field
In real numbers, divisions are just that: divisions.
With integers, I did mention divisions become problematic when attempting to naively divide two numbers as if we were trying to divide real numbers.
For example, yields in real numberes, but things get awkward in integers.
Recall also that in real numbers, that there indeed exists some and such that . This is because a multiplicative inverse for exists in real numbers. Nothing like that exists in integers.
And this is why we use finite fields.
Finite field math is often coupled with modular arithmetics, and modular arithmetics pretty much has things "wrap around". With the help of the extended Euclidean algorithm, when attempting to find the modular inverse of , we're looking for something that when multiplied by it, the product will "wrap around" to .
I've also mentioned that a notation for in real numbers is , and we can do the same in finite fields.
Better yet, many mathematicians express the congruence (where is prime) as just
This brings us to divisions in finite field.
Divisions in finite field simply involves finding the multplicative inverse of the denominator (a.k.a. the divisor). Once found the multiplicative inverse, we take that value and multiply the "dividend" with the computed multiplicative inverse.
The cyclic group
Elliptic curves in finite field forms not only an Abelian group, that is, it satisfies the commutative, associative, identity, and inverse properties, but it also forms a cyclic group.
What it means for something to be a cyclic is that there exists some element in the group—called the Generator—such that its scalar multiplication or exponentiation yields every element in the group.
In the case of elliptic curves, given the coefficients and for the Weierstrass equation, and the prime field, there exists a finite number of points on the curve, denoted as . In a lot of these curves, ther could exist one point on the curve such that for every coefficient in , the multiple will yield every point on the curve. In this case, is known as the generator.
Putting it all together
We've defined the math of finding a third point on an elliptic curve. The act of flipping that "third point" on the curve vertically is the algorithm of an elliptic curve group "addition".
Now that we know about the math, let's put this all together with finite field math.
Recall that real numbers form a field.
Not only is the computation of a third point on the curve can be done in the real number field, but we can also do the same computation with finite field of prime order. Since finite fields are fields, the curve equation works perfectly with finite fields.
The only difference being that everything happens modulo a prime for the finite field, and that division isn't simply the act of finding how many times the divisor fits inside the dividend, but instead, we compute the multiplicative inverse, such that the product of the divisor by the multiplicative inverse of yield (where is the multiplicative inverse, and that is prime).
Application to cryptography
Elliptic curve group arithmetic in finite field of prime order is the math that is used to take full advantage of the hardness of the solution to the discrete log problem. And because it is known to be difficult to solve (on a classical computer), it is an excellent cryptographic primitive for various cryptographic schemes in cybersecurity applications.
First thing's first: public and private keys
The discrete log problem stipulates that given some 2-parameter group operation (such the elliptic curve "addition"), given some positive integer , and a group element , we can compute the scalar multiplication , where having access to and/or is not at all adequate to find the integer . In order to recover , we will actually need to physically steal it.
Thus, the integer can be regarded as private information, and , and can be shared publicly.
In real-world applications, is typically some standardized parameter, such as the G variable that is defined in the secp256r1 specification. Thus is never explicitly shared by either communicating parties, but instead has been agreed upon, and already known by everyone, and ahead of time.
The only thing that "belongs" to someone is the scalar multiplication . For example, Alice can generate her secret number , and she can use it to derive . She would share the result of the scalar multiplication , but she will never share on it's own; it's a secret. Again, by the nature of the hardness of the discrete log problem can never be extracted from .
In the real world, is the private key, and is the public key.
The curve parameters
When Alice and Bob wants to engage in a transaction that involves elliptic curves, it is a good idea for them to work with provably secure parameters that many applications are aware of.
Earlier I mentioned "secp256r1".
secp256r1 is an example of standard curve parameters.
It stipulates
- the order of the finite field (the prime number that represents the order of the field, which is the total number of elements in the field)
- the value of the and coefficients of the equation in Weierstrass form
- the generator point
The parameters also includes numbers that would have otherwise needed to be computed, such as the order of the curve –which is the total number of points on the curve, including the point at infinity.
In fact, the will be the most helpful, since it's ideal if coefficients avoid ever equaling , since doing so will yield the point at infinity.
How these points are chosen
Typically, cryptographers would pick some arbitrary prime , and points and . Then count the total number of points on the curve to derive . If is a prime, there would only ever be one cyclic subgroup, and thus one generator , such that multiplying it with every value in will yield every point on the curve, including the point at infinity.
Next is to find some point such that yields the point at infinity.
Thus we have our , , and parameters of our curve, and the derivations of the order , and our generator , such that .
Key exchange, for encryption
ECC isn't typically used for encryption.
That said, we can use ECC for deriving a shared secret, which is then used against a symmetric cipher, such as AES.
So we've established that extracting the scalar coefficient in an elliptic curve scalar multiplication is prohibitively difficult to do.
We've also established that ellitpic curve arithmetic forms an Abelian group, with associative properties.
This means that not only can Alice derive her public key , but she can then send it to Bob, so that Bob, using his private key can derive . And Bob can likewise send his public key to Alice, and she can then compute .
And due to the commutative nature, .
Both Alice and Bob should land on the same value on the Elliptic curve, and neither of them will have ever shared nor , and no one can extract those values.
How shared secrets are used
Typically, once the shared curve point on an elliptic curve has been established, the -coordinate of the curve point is used as the input to a key-derivation function (KDF).
Typically, the KDF used is HKDF. It has the most provable security, and it is strongly resistant against key material weakness.
For HKDF, we need some cryptographically-secure salt, and our derived -coordinate from our key exchange. Once derived, we should then have a secure key, from which it is impossible to derive the shared -coordinate.
The derived key and a plaintext is then input into a cipher, such as AES-256-GCM (of course, along with cryptographically-random initialization vector).
The decryptor will then take the derived key to decrypt the message.
Digital signatures
Digital signatures involves having Alice prove that she sent a message, by "signing" it using her private key, and Bob can then "verify" the signature against the message using Alice's public key.
The most widely used digital signature algorithm is ECDSA.
This is how it works.
Let's say Alice wants to send a message to Bob, and she signs it using her private key .
Alice would send to Bob two values, represented in the following tuple:
Where is a totally random number between and , and is some hash function such as .
And note: that tuple does not represent any point on the curve! and are two distinct values.
Alice sends to Bob, and when Bob wants to verify the signature using Alice's public key , he'd compute
Bob will absolutely know that the signature is valid if
How digital signature verification works
Even though Bob has no clue about the values and that was used by Alice to compute how and , but as long as Bob is aware of the overall algorithm, he can know how to derive , even if he doesn't know .
Expanding the above , we get
From the above equation, we can factor out
Then the denominator cancels out parts of the nominator, and finally all we are left with is , from which, the -coordinate should equal to Alice's supplied .
Conclusion
Elliptic curve cryptography leverages group operations on an elliptic curve in finite fields of prime order, in projective plane geometry.
Multiplying the generator of the curve by some will yield some point in time by taking advantage of elliptic curve Abelian commutative properties, without ever revealing to anyone what is. Most importantly, there are no known efficient algorithm to recover without an exhaustive search. In other words, easy to compute one way, but hard to go the other, which is the basis of most cryptosystems.
We're then able to exploit this property and use it in various cryptographic use cases. The simplest example is deriving a shared secret between Alice and Bob, by having them share each other's publicly available point on the curve, then having each of them then multiply it with their own secret number to derive the shared secret.